
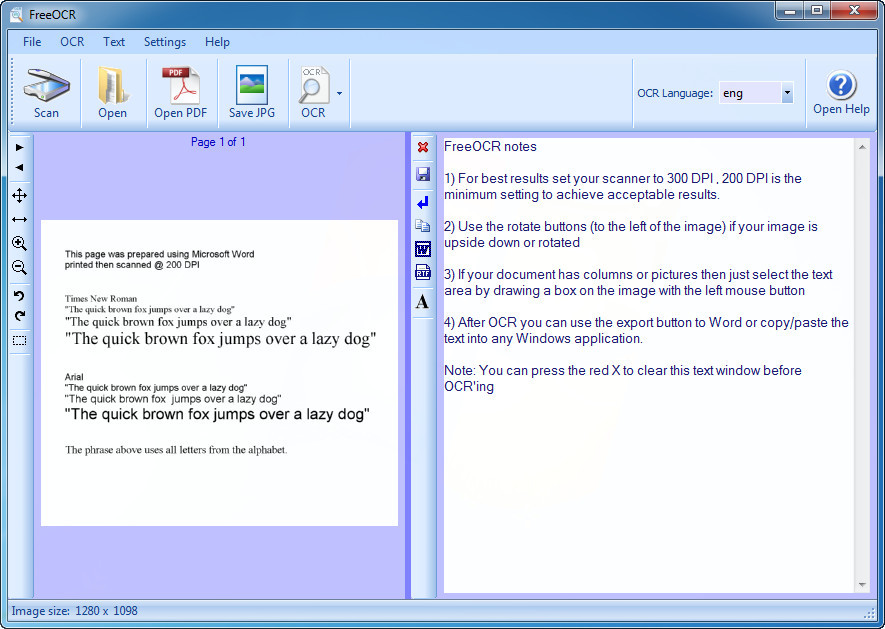
FreeOCR - это полностью бесплатная программа для оптического распознавания отсканированного текста в операционной системе Windows. Она поддерживает прямой импорт отсканированного текста с большинства сканеров, умеет открывать большинство многостраничных Tiff-изображений и отсканированных PDF-файлов, а также популярных форматов файлов изображений. Сохранение распознанного текста возможно как в виде простого текстового файла, так в формат Microsoft Word.
Несмотря на то, что интерфейс программы не переведен на русский язык, обилие иконок наглядно показывающих предназначение кнопок, поможет пользователям не знающим английского языка. Главное окно программы поделено на две части, в одной из которых отображается отсканированный текст, а в другой - результат распознавания. Актуальные версии программы поддерживают распознавание русского текста, однако не будем лукавить, изначально программа «заточена» на работу с английским, немецким, французским, итальянским и испанским языками.
Кстати, русский язык не входит в базовую установку программы. Для распознавания текстов на русском необходимо скачать дополнительный файл rus.traineddata, после чего в программе открыть меню Settings → Open Language Folder, скопировать файл rus.traineddata в открывшуюся папку и перезапустить программу. После этого в выпадающем списке OCR Language (языков доступных для распознавания текстов) появится русский язык (rus) .
Использование в FreeOCR новейшей версии движка распознавания Tesseract (v3.01) позволило значительно повысить точность анализа макетов страниц, что дает возможность запускать процесс распознавания без предварительного использования инструмента выделения текстовых зон.
В целом, программа очень проста в установке и использовании, а поддержка работы с многостраничными файлами в формате tiff, документами Adobe PDF и факсами, а так же большинством типов изображений, включая сжатые Tiff (которые изначально не поддерживались движком распознавания) делают её действительно универсальным инструментом. Как уже говорилось, движок может напрямую работать с большинством современных сканеров по протоколам Twain и WIA, однако сохранение отсканированных файлов возможно лишь в формат JPG. На своем официальном сайте авторы обещали включить поддержку сохранения в формат PDF, однако, учитывая, что последняя версия программы была выпущена в 2015 году, особо рассчитывать на это не приходится.
Кстати, OCR-движок Tesseract, включенный в состав программы, изначально разрабатывался в лаборатории Hewlett Packard в период с 1985 по 1995 год. На конкурсе организованном Университетом Невады в Лас-Вегасе он вошел в тройку победителей. В наше время поддержка кода движка осуществляется компанией Google, которая распространяет его под лицензией Apache V2.0. Сама же FreeOCR распространяется полностью бесплатно, вы можете применять её так как вам необходимо, включая коммерческое использование.
Скриншоты и видео:



| Категория: | |
| Системы: |
Windows
|
| Размер: | 10,8 Мб |
| Автор: | FreeOCR ( Сайт) |
| Языки: |
Английский
|
| Лицензия: | Freeware (Бесплатная) |
| Обновление: | 01.06.2018 |
| Версия: | 5.4.1 |